

















模型:
beomi/KcELECTRA-base


 英文
英文KcELECTRA:韩语评论ELECTRA
** 2022.10.08更新 **
- KcELECTRA-base-v2022(先前为v2022-dev)模型名称已更改。--> 已与KcELECTRA-base库的v2022整合
- 添加了模型的详细分数。
- 在大多数下游任务中,与原始的KcELECTRA-base(v2021)相比,有大约1%的性能提升。
大多数公开的韩语Transformer模型都是基于韩语维基百科、新闻文章、书籍等经过精心处理的数据进行训练的。然而,实际上像NSMC这样的用户生成的噪声文本领域的数据集并没有被精心处理过,存在很多口语化特点和大量的新术语以及正式写作中不会出现的错别字等表达。
为了将KcELECTRA应用于具有上述特征的数据集,我们从Naver新闻中收集了评论和回复,并从头开始训练了Tokenizer和ELECTRA模型的预训练ELECTRA模型。
通过增加数据集和扩展词汇表,KcELECTRA的性能得到了显著改善。
您可以使用Huggingface的Transformers库轻松加载KcELECTRA并使用它(无需下载任何文件)。
💡 NOTE 💡 General Corpus로 학습한 KoELECTRA가 보편적인 task에서는 성능이 더 잘 나올 가능성이 높습니다. KcBERT/KcELECTRA는 User genrated, Noisy text에 대해서 보다 잘 동작하는 PLM입니다.
KcELECTRA性能
- Finetune代码可以在 https://github.com/Beomi/KcBERT-finetune 处找到。
- 您可以在该Repo的每个Checkpoint文件夹中查看每个步骤的详细分数。
| Size (용량) | NSMC (acc) | Naver NER (F1) | PAWS (acc) | KorNLI (acc) | KorSTS (spearman) | Question Pair (acc) | KorQuaD (Dev) (EM/F1) | |
|---|---|---|---|---|---|---|---|---|
| KcELECTRA-base-v2022 | 475M | 91.97 | 87.35 | 76.50 | 82.12 | 83.67 | 95.12 | 69.00 / 90.40 |
| KcELECTRA-base | 475M | 91.71 | 86.90 | 74.80 | 81.65 | 82.65 | 95.78 | 70.60 / 90.11 |
| KcBERT-Base | 417M | 89.62 | 84.34 | 66.95 | 74.85 | 75.57 | 93.93 | 60.25 / 84.39 |
| KcBERT-Large | 1.2G | 90.68 | 85.53 | 70.15 | 76.99 | 77.49 | 94.06 | 62.16 / 86.64 |
| KoBERT | 351M | 89.63 | 86.11 | 80.65 | 79.00 | 79.64 | 93.93 | 52.81 / 80.27 |
| XLM-Roberta-Base | 1.03G | 89.49 | 86.26 | 82.95 | 79.92 | 79.09 | 93.53 | 64.70 / 88.94 |
| HanBERT | 614M | 90.16 | 87.31 | 82.40 | 80.89 | 83.33 | 94.19 | 78.74 / 92.02 |
| KoELECTRA-Base | 423M | 90.21 | 86.87 | 81.90 | 80.85 | 83.21 | 94.20 | 61.10 / 89.59 |
| KoELECTRA-Base-v2 | 423M | 89.70 | 87.02 | 83.90 | 80.61 | 84.30 | 94.72 | 84.34 / 92.58 |
| KoELECTRA-Base-v3 | 423M | 90.63 | 88.11 | 84.45 | 82.24 | 85.53 | 95.25 | 84.83 / 93.45 |
| DistilKoBERT | 108M | 88.41 | 84.13 | 62.55 | 70.55 | 73.21 | 92.48 | 54.12 / 77.80 |
* HanBERT的大小是Bert模型和Tokenizer DB的总和。
* 结果是使用相同的配置运行的,如果进行了超参数调整,可能会获得更好的性能。
如何使用
要求
- pytorch ~= 1.8.0
- transformers ~= 4.11.3
- emoji ~= 0.6.0
- soynlp ~= 0.0.493
默认用法
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("beomi/KcELECTRA-base")
model = AutoModel.from_pretrained("beomi/KcELECTRA-base")
💡 如果您在先前的KcBERT相关代码中使用了AutoTokenizer和AutoModel,请只需将.from_pretrained("beomi/kcbert-base")更改为.from_pretrained("beomi/KcELECTRA-base")即可立即使用。
Pretrain&Finetune Colab链接集合
预训练数据- 使用于KcBERT训练的数据+之后收集的评论直到2021.03月初
- 约17GB
- 基于评论-回复的文档组成
- https://github.com/KLUE-benchmark/KLUE-ELECTRA 通过Repo进行预训练
- https://github.com/Beomi/KcBERT-finetune 通过Repo进行Finetune和Score比较
- 使用PyTorch-Lightning 1.3.0、GPU、Colab的NSMC

训练数据和预处理
原始数据
训练数据是收集了2019.01.01至2021.03.09之间发表的评论丰富的新闻/或整个新闻文章的评论和回复的数据。
数据大小约为17.3GB,由超过一亿八千万个句子组成。
在KcBERT中,我们使用2019.01-2020.06的文本进行训练,处理后的文本约有九千万个句子。
预处理
进行PLM训练所进行的预处理过程如下:
安装下面的clean函数后,应用于文本数据,这将提高下游任务的性能(减少[UNK])。
pip install soynlp emoji
请使用以下clean函数于文本数据中。
import re
import emoji
from soynlp.normalizer import repeat_normalize
emojis = ''.join(emoji.UNICODE_EMOJI.keys())
pattern = re.compile(f'[^ .,?!/@$%~%·∼()\x00-\x7Fㄱ-ㅣ가-힣{emojis}]+')
url_pattern = re.compile(
r'https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*)')
import re
import emoji
from soynlp.normalizer import repeat_normalize
pattern = re.compile(f'[^ .,?!/@$%~%·∼()\x00-\x7Fㄱ-ㅣ가-힣]+')
url_pattern = re.compile(
r'https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*)')
def clean(x):
x = pattern.sub(' ', x)
x = emoji.replace_emoji(x, replace='') #emoji 삭제
x = url_pattern.sub('', x)
x = x.strip()
x = repeat_normalize(x, num_repeats=2)
return x
💡 在Finetune Score中,未应用上述clean函数。
清理后的数据
- 预计整理并公开KcBERT以外的其他数据。
Tokenizer,模型训练
Tokenizer是通过Huggingface的 Tokenizers 库进行训练的。
我们使用BertWordPieceTokenizer进行训练,并将词汇表大小设置为30000。
进行Tokenizer训练时,我们使用了整个数据集,并在与KoELECTRA重叠的部分之外额外添加了KoELECTRA未使用的Vocab(实际上,这两个模型之间的重叠部分约为5000个标记)。
我们使用TPU v3-8进行了约10天的训练,并且目前在Huggingface上公开了训练步骤为848k的模型权重。
(通过每100k步的Checkpoint进行性能评估。关于此部分,请参考KcBERT-finetune repo)
模型训练损失可以看到在最初的100-200k步骤之间,损失急剧下降,之后一直下降直到训练结束。
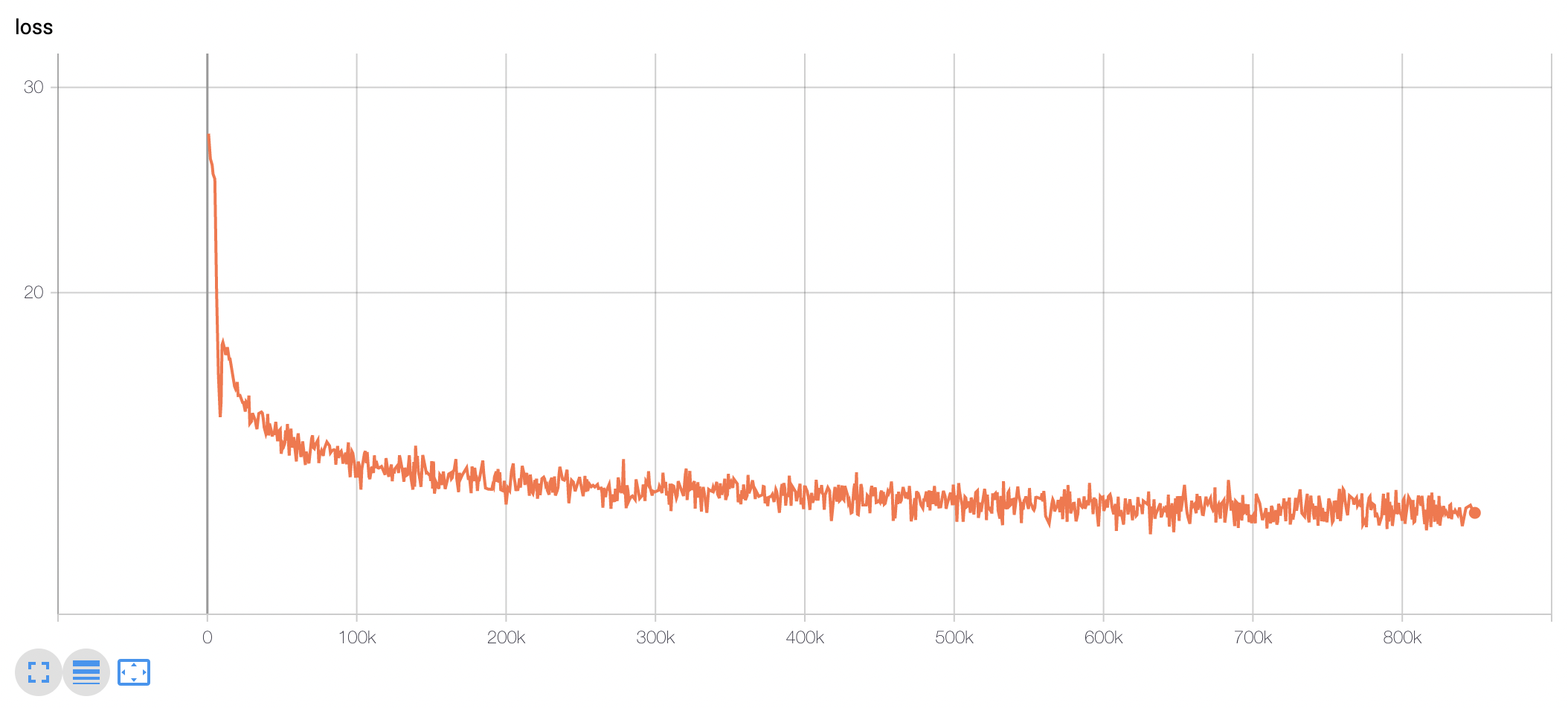
KcELECTRA根据预训练步骤的下游任务性能比较
💡 下表仅显示了部分测试结果,而不是所有的checkpoint。
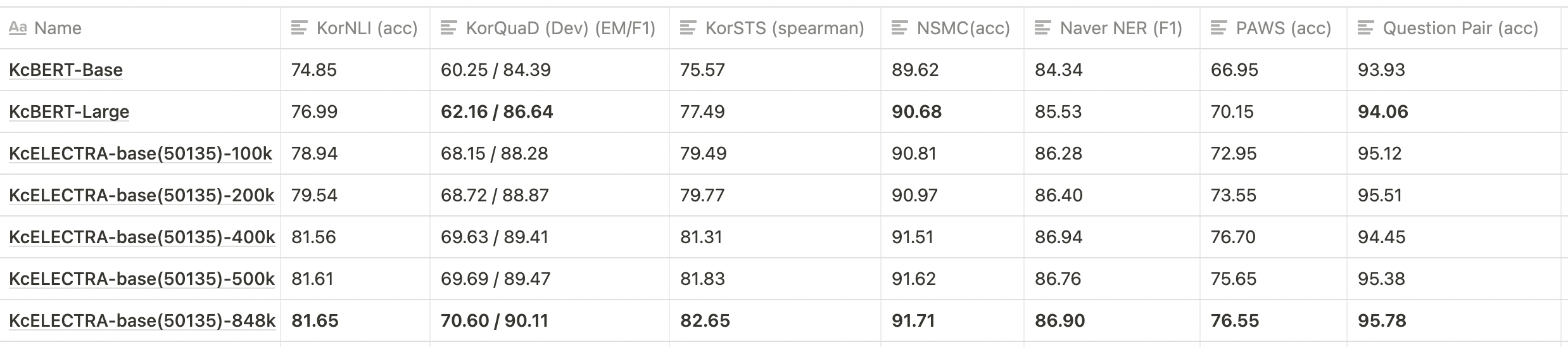
- KcELECTRA-base在所有数据集上都比KcBERT-base和KcBERT-large具有更好的性能。
- 可以看到随着预训练步骤的增加,KcELECTRA的性能逐渐提高。
引用/Citation
当引用KcELECTRA时,请使用以下格式进行引用。
@misc{lee2021kcelectra,
author = {Junbum Lee},
title = {KcELECTRA: Korean comments ELECTRA},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/Beomi/KcELECTRA}}
}
除了通过论文引用之外,请注明MIT许可证。☺️
致谢
感谢GCP/TPU环境中Zeta36计划的支持,用于训练KcELECTRA模型。
感谢 Monologg 先生在模型训练过程中提供的许多建议 :)
参考资料
Github Repos
- KcBERT by Beomi
- BERT by Google
- KoBERT by SKT
- KoELECTRA by Monologg
- Transformers by Huggingface
- Tokenizers by Hugginface
- ELECTRA train code by KLUE