

















模型:
TheBloke/wizardLM-13B-1.0-GPTQ


 中文
中文
Chat & support: my new Discord server
Want to contribute? TheBloke's Patreon page
WizardLM 13B 1.0 GPTQ
These files are GPTQ 4bit model files for WizardLM 13B 1.0 .
It is the result of merging the LoRA then quantising to 4bit using GPTQ-for-LLaMa .
Other repositories available
- 4-bit GPTQ models for GPU inference
- 4-bit, 5-bit and 8-bit GGML models for CPU(+GPU) inference
- Merged, unquantised fp16 model in HF format
Prompt Template
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: prompt goes here ASSISTANT:
How to easily download and use this model in text-generation-webui
Open the text-generation-webui UI as normal.
Provided files
WizardLM-13B-1.0-GPTQ-4bit-128g.no-act-order.safetensors
This will work with all versions of GPTQ-for-LLaMa. It has maximum compatibility.
It was created with groupsize 128 to ensure higher quality inference, without --act-order parameter to maximise compatibility.
-
WizardLM-13B-1.0-GPTQ-4bit-128g.no-act-order.safetensors
- Works with all versions of GPTQ-for-LLaMa code, both Triton and CUDA branches
- Works with AutoGPTQ
- Works with text-generation-webui one-click-installers
- Parameters: Groupsize = 128. No act-order.
-
Command used to create the GPTQ:
python llama.py /workspace/process/wizardLM-13B-1.0/HF wikitext2 --wbits 4 --true-sequential --groupsize 128 --save_safetensors /workspace/process/wizardLM-13B-1.0/gptq/WizardLM-13B-1.0-GPTQ-4bit-128g.no-act-order.safetensors
Discord
For further support, and discussions on these models and AI in general, join us at:
Thanks, and how to contribute.
Thanks to the chirper.ai team!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
- Patreon: https://patreon.com/TheBlokeAI
- Ko-Fi: https://ko-fi.com/TheBlokeAI
Patreon special mentions : Aemon Algiz, Dmitriy Samsonov, Nathan LeClaire, Trenton Dambrowitz, Mano Prime, David Flickinger, vamX, Nikolai Manek, senxiiz, Khalefa Al-Ahmad, Illia Dulskyi, Jonathan Leane, Talal Aujan, V. Lukas, Joseph William Delisle, Pyrater, Oscar Rangel, Lone Striker, Luke Pendergrass, Eugene Pentland, Sebastain Graf, Johann-Peter Hartman.
Thank you to all my generous patrons and donaters!
Original model card: WizardLM 13B 1.0
WizardLM: An Instruction-following LLM Using Evol-Instruct
Empowering Large Pre-Trained Language Models to Follow Complex Instructions

News
At present, our core contributors are preparing the 33B version and we expect to empower WizardLM with the ability to perform instruction evolution itself, aiming to evolve your specific data at a low cost.
- 🔥 We released 13B version of WizardLM trained with 250k evolved instructions (from ShareGPT). Checkout the Demo_13B , Demo_13B_bak and the GPT-4 evaluation. Please download our delta model at the following link .
- 🔥 We released 7B version of WizardLM trained with 70k evolved instructions (from Alpaca data). Checkout the paper and Demo_7B , Demo_7B_bak
- 📣 We are looking for highly motivated students to join us as interns to create more intelligent AI together. Please contact caxu@microsoft.com
Note for 13B model usage: To obtain results identical to our demo , please strictly follow the prompts and invocation methods provided in the "src/infer_wizardlm13b.py" to use our 13B model for inference. Unlike the 7B model, the 13B model adopts the prompt format from Vicuna and supports multi-turn conversation.
Note for demo usage: We only recommend using English to experience our model. Support for other languages will be introduced in the future. The demo currently only supports single-turn conversation.
GPT-4 automatic evaluation
We adopt the automatic evaluation framework based on GPT-4 proposed by FastChat to assess the performance of chatbot models. As shown in the following figure, WizardLM-13B achieved better results than Vicuna-13b.
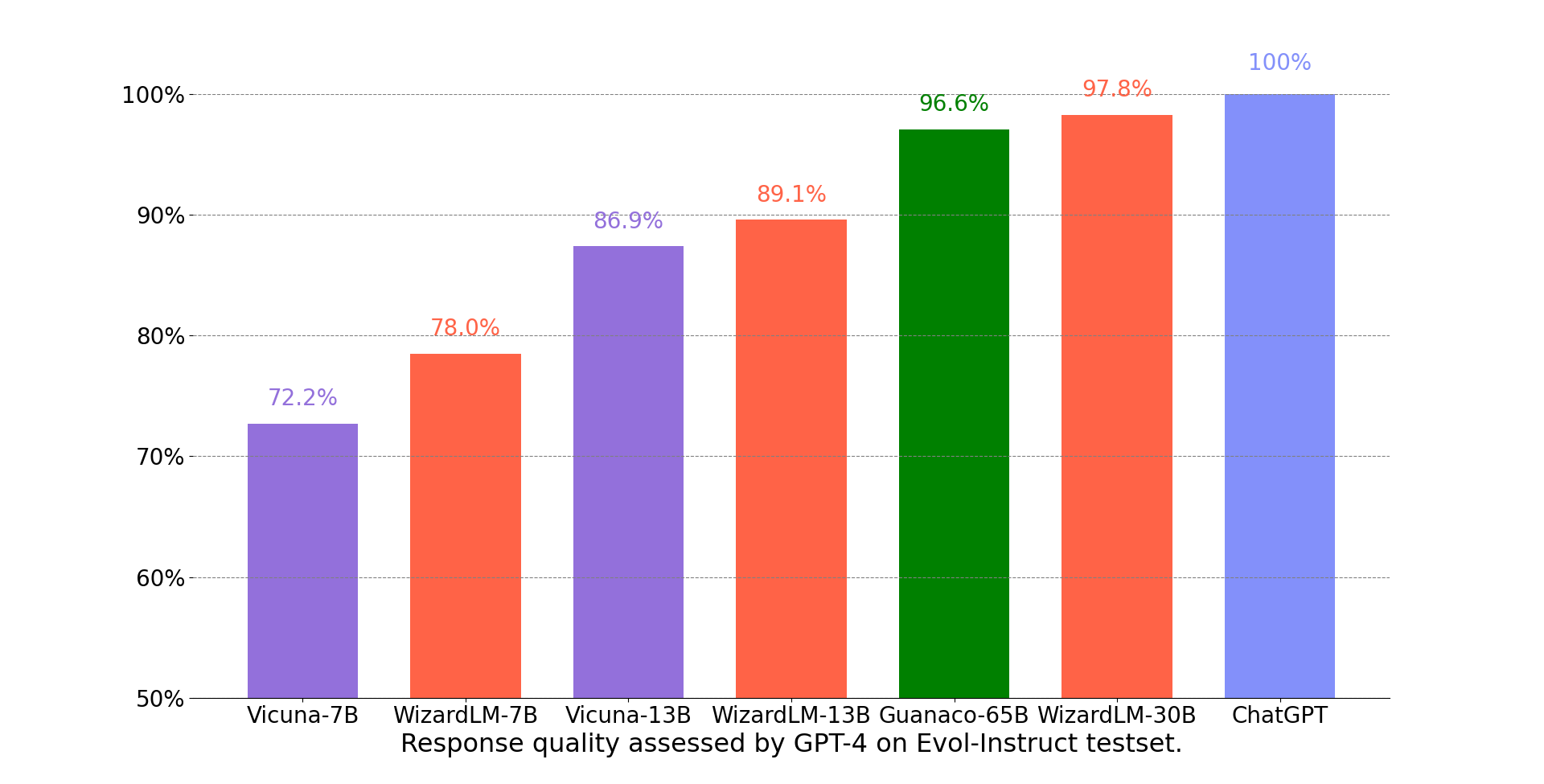
WizardLM-13B performance on different skills.
The following figure compares WizardLM-13B and ChatGPT’s skill on Evol-Instruct testset. The result indicates that WizardLM-13B achieves 89.1% of ChatGPT’s performance on average, with almost 100% (or more than) capacity on 10 skills, and more than 90% capacity on 22 skills.
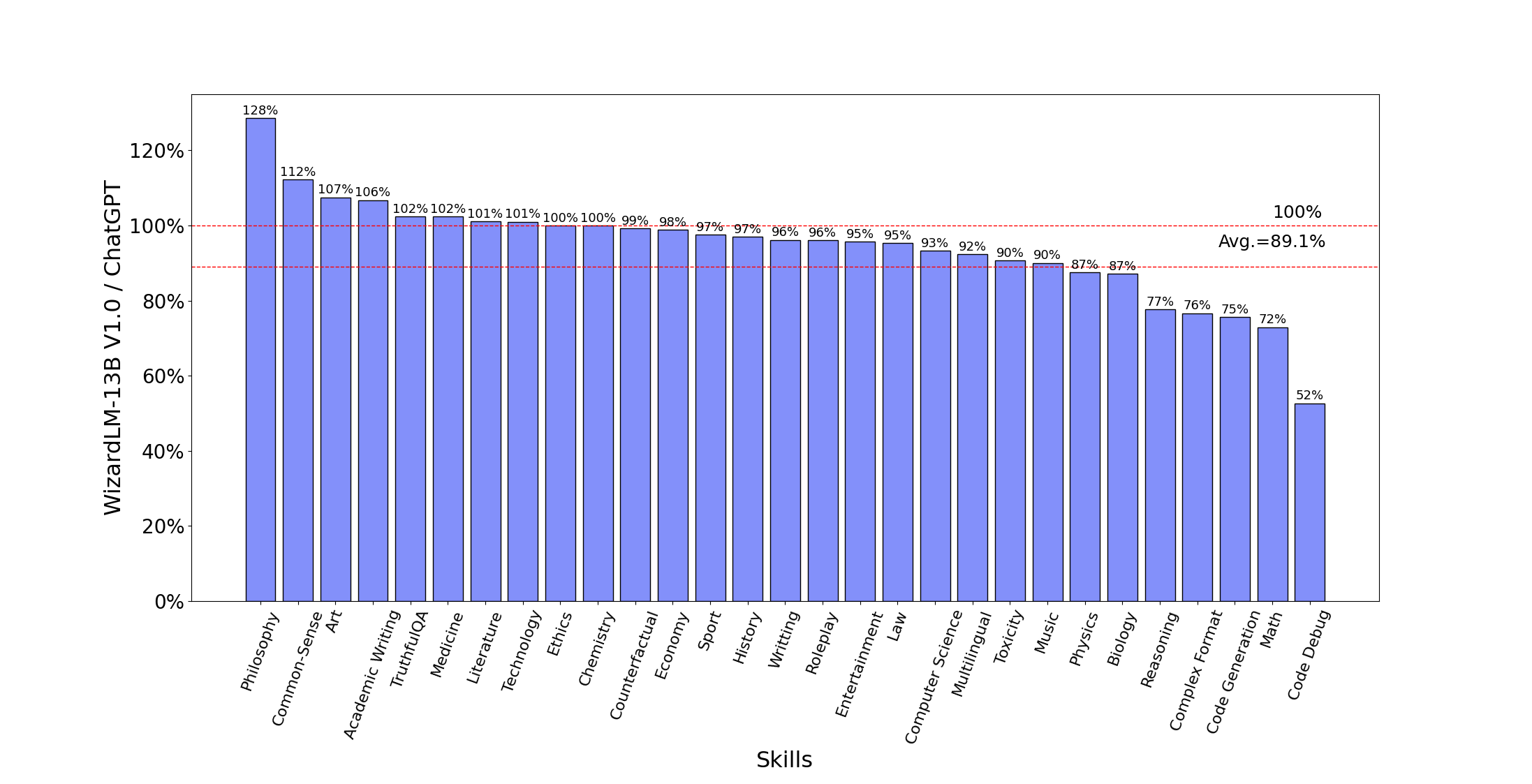
Call for Feedbacks
We welcome everyone to use your professional and difficult instructions to evaluate WizardLM, and show us examples of poor performance and your suggestions in the issue discussion area. We are focusing on improving the Evol-Instruct now and hope to relieve existing weaknesses and issues in the the next version of WizardLM. After that, we will open the code and pipeline of up-to-date Evol-Instruct algorithm and work with you together to improve it.
Unofficial Video Introductions
Thanks to the enthusiastic friends, their video introductions are more lively and interesting.
Case Show
We just sample some cases to demonstrate the performance of WizardLM and ChatGPT on data of varying difficulty, and the details pls refer Case Show .
Overview of Evol-Instruct
Evol-Instruct is a novel method using LLMs instead of humans to automatically mass-produce open-domain instructions of various difficulty levels and skills range, to improve the performance of LLMs.
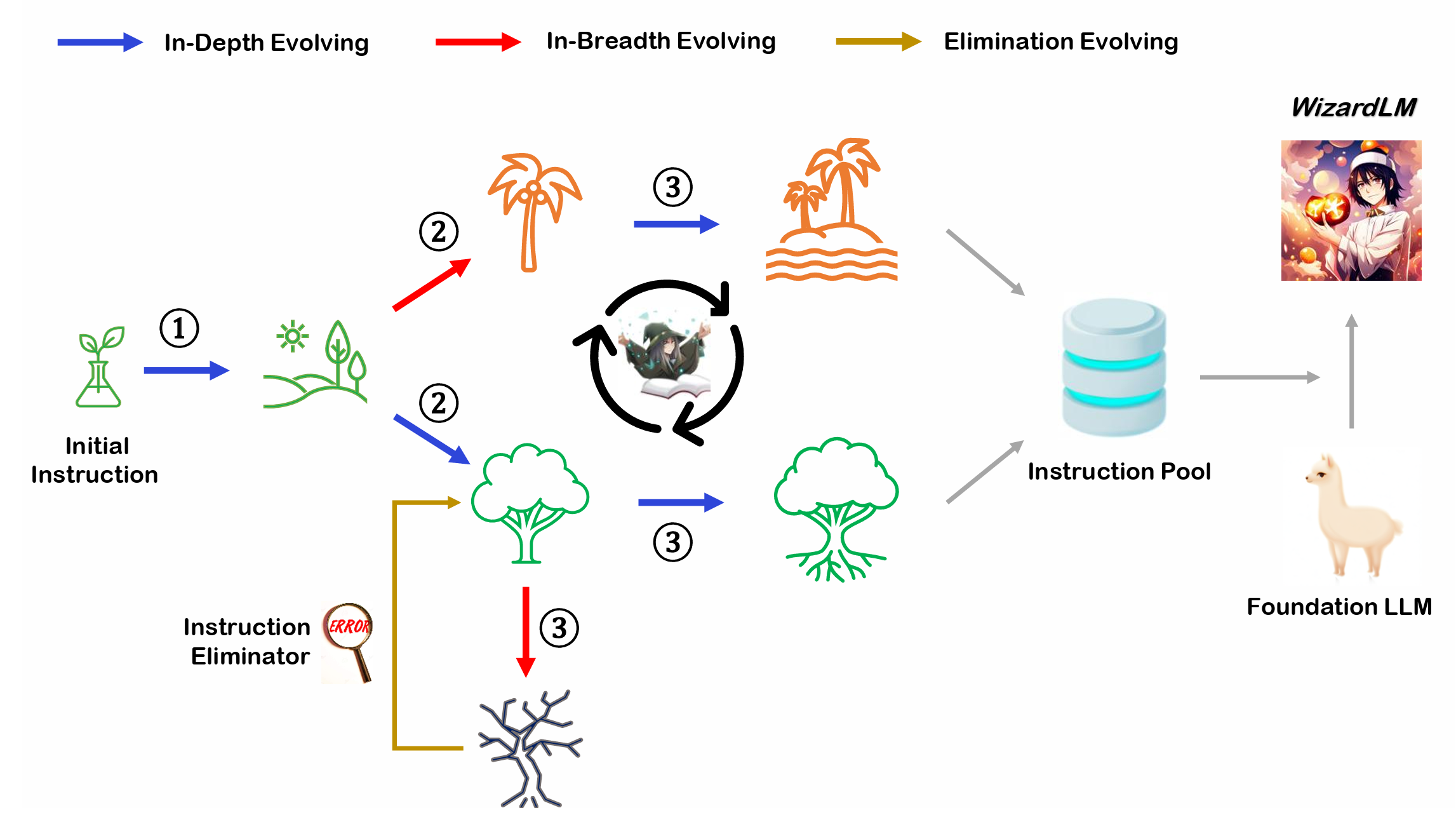
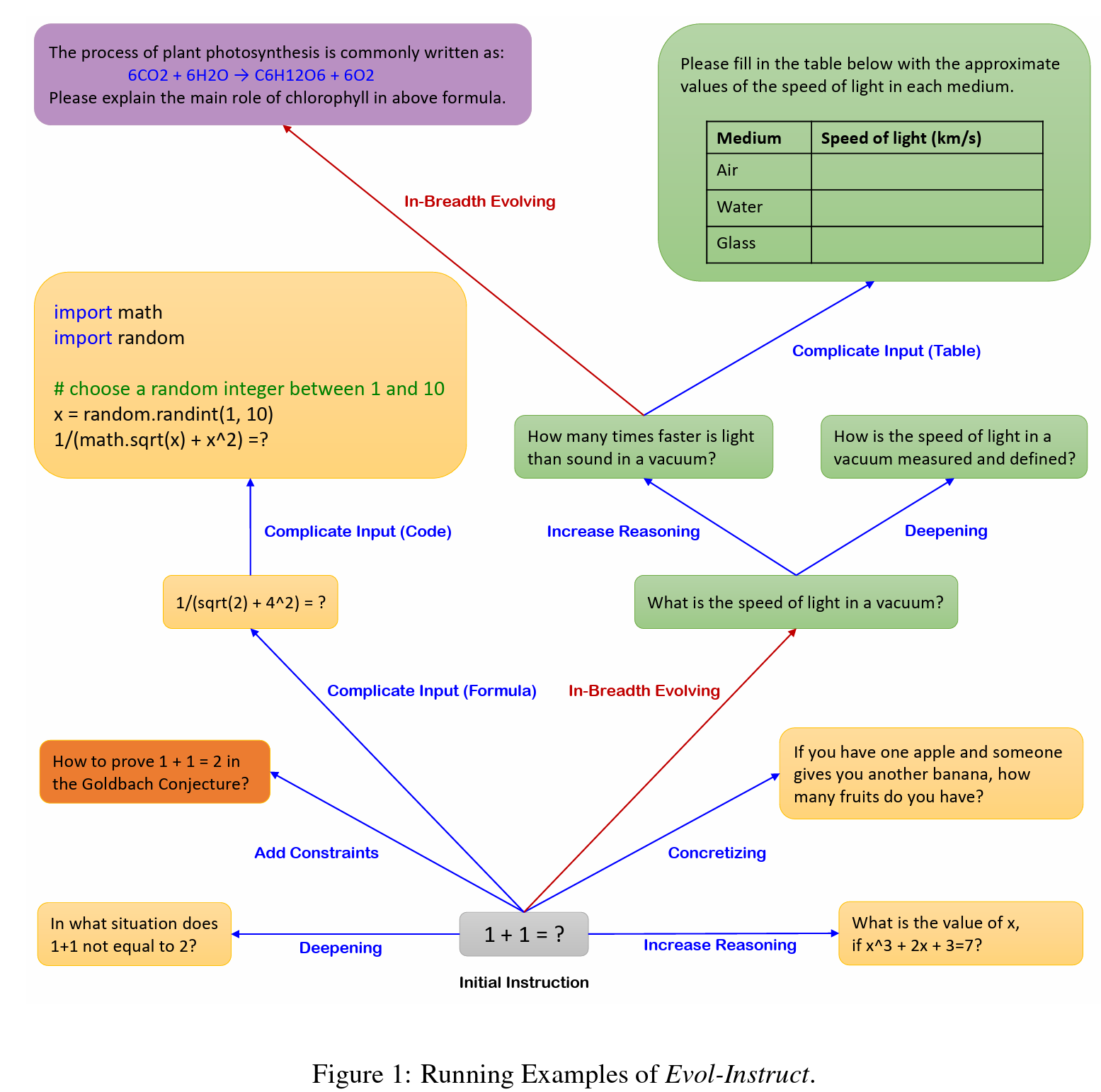
Contents
Online Demo
Training Data
WizardLM Weights
Fine-tuning
Distributed Fine-tuning
Inference
Evaluation
Citation
Disclaimer
Online Demo
We will provide our latest models for you to try for as long as possible. If you find a link is not working, please try another one. At the same time, please try as many real-world and challenging problems that you encounter in your work and life as possible. We will continue to evolve our models with your feedbacks.
Training Data
alpaca_evol_instruct_70k.json contains 70K instruction-following data generated from Evol-Instruct. We used it for fine-tuning the WizardLM model. This JSON file is a list of dictionaries, each dictionary contains the following fields:
- instruction : str , describes the task the model should perform. Each of the 70K instructions is unique.
- output : str , the answer to the instruction as generated by gpt-3.5-turbo .
WizardLM Weights
We release [WizardLM] weights as delta weights to comply with the LLaMA model license. You can add our delta to the original LLaMA weights to obtain the WizardLM weights. Instructions:
python src/weight_diff_wizard.py recover --path_raw <path_to_step_1_dir> --path_diff <path_to_step_2_dir> --path_tuned <path_to_store_recovered_weights>
Fine-tuning
We fine-tune WizardLM using code from Llama-X . We fine-tune LLaMA-7B and LLaMA-13B with the following hyperparameters:
| Hyperparameter | LLaMA-7B | LLaMA-13B |
|---|---|---|
| Batch size | 64 | 384 |
| Learning rate | 2e-5 | 2e-5 |
| Epochs | 3 | 3 |
| Max length | 2048 | 2048 |
| Warmup step | 2 | 50 |
| LR scheduler | cosine | cosine |
To reproduce our fine-tuning of WizardLM, please follow the following steps:
deepspeed train_freeform.py \
--model_name_or_path /path/to/llama-7B/hf \
--data_path /path/to/alpaca_evol_instruct_70k.json \
--output_dir /path/to/wizardlm-7B/hf/ft \
--num_train_epochs 3 \
--model_max_length 2048 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 800 \
--save_total_limit 3 \
--learning_rate 2e-5 \
--warmup_steps 2 \
--logging_steps 2 \
--lr_scheduler_type "cosine" \
--report_to "tensorboard" \
--gradient_checkpointing True \
--deepspeed configs/deepspeed_config.json \
--fp16 True
Distributed Fine-tuning
See Distributed Fine-tuning
Inference
We provide the decoding script for WizardLM, which reads a input file and generates corresponding responses for each sample, and finally consolidates them into an output file.
You can specify base_model , input_data_path and output_data_path in src\inference_wizardlm.py to set the decoding model, path of input file and path of output file. The decoding command:
python src\inference_wizardlm.py
Evaluation
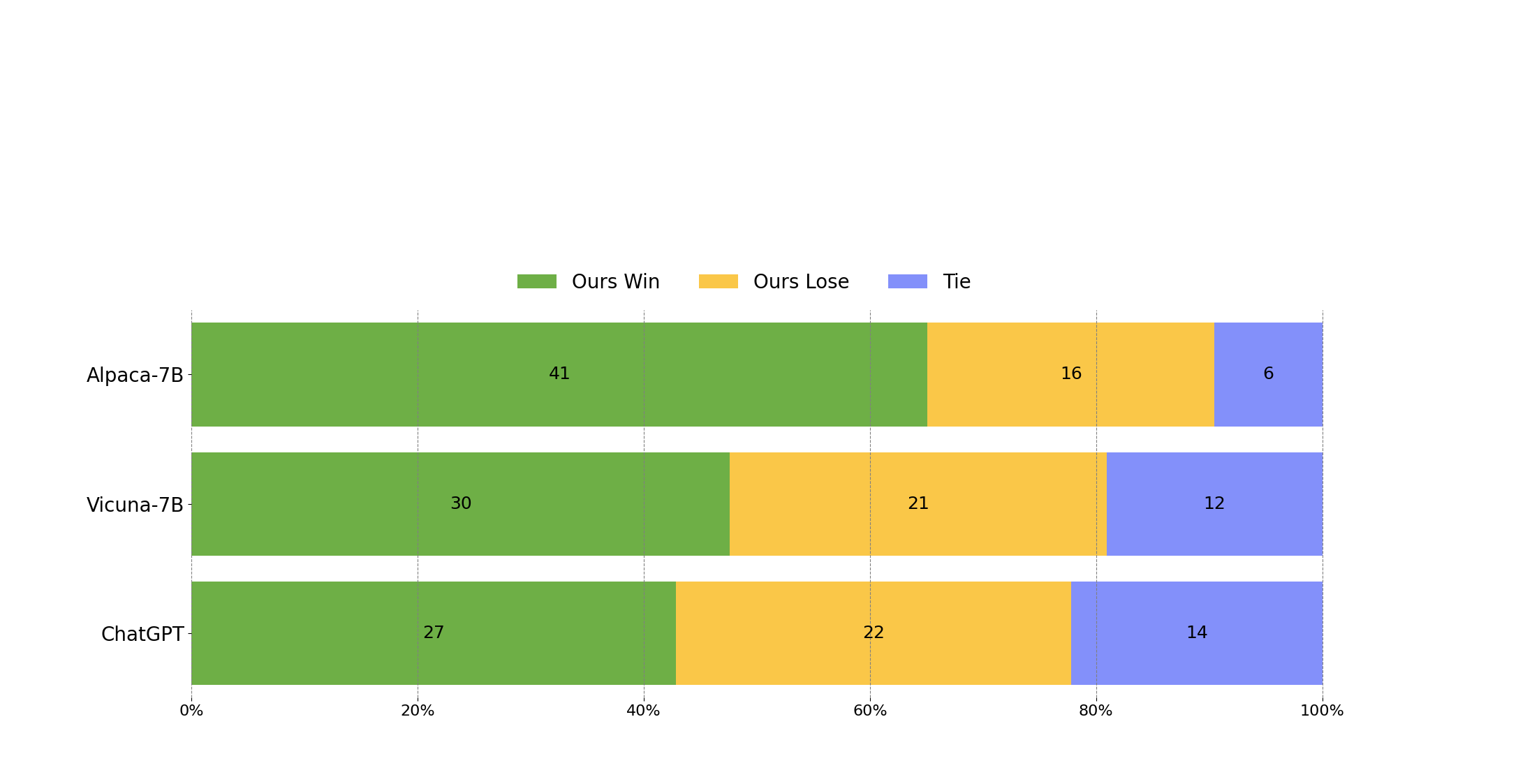
To evaluate Wizard, we conduct human evaluation on the inputs from our human instruct evaluation set WizardLM_testset.jsonl . This evaluation set was collected by the authors and covers a diverse list of user-oriented instructions including difficult Coding Generation & Debugging, Math, Reasoning, Complex Formats, Academic Writing, Extensive Disciplines, and so on. We performed a blind pairwise comparison between Wizard and baselines. Specifically, we recruit 10 well-educated annotators to rank the models from 1 to 5 on relevance, knowledgeable, reasoning, calculation and accuracy.
WizardLM achieved significantly better results than Alpaca and Vicuna-7b.
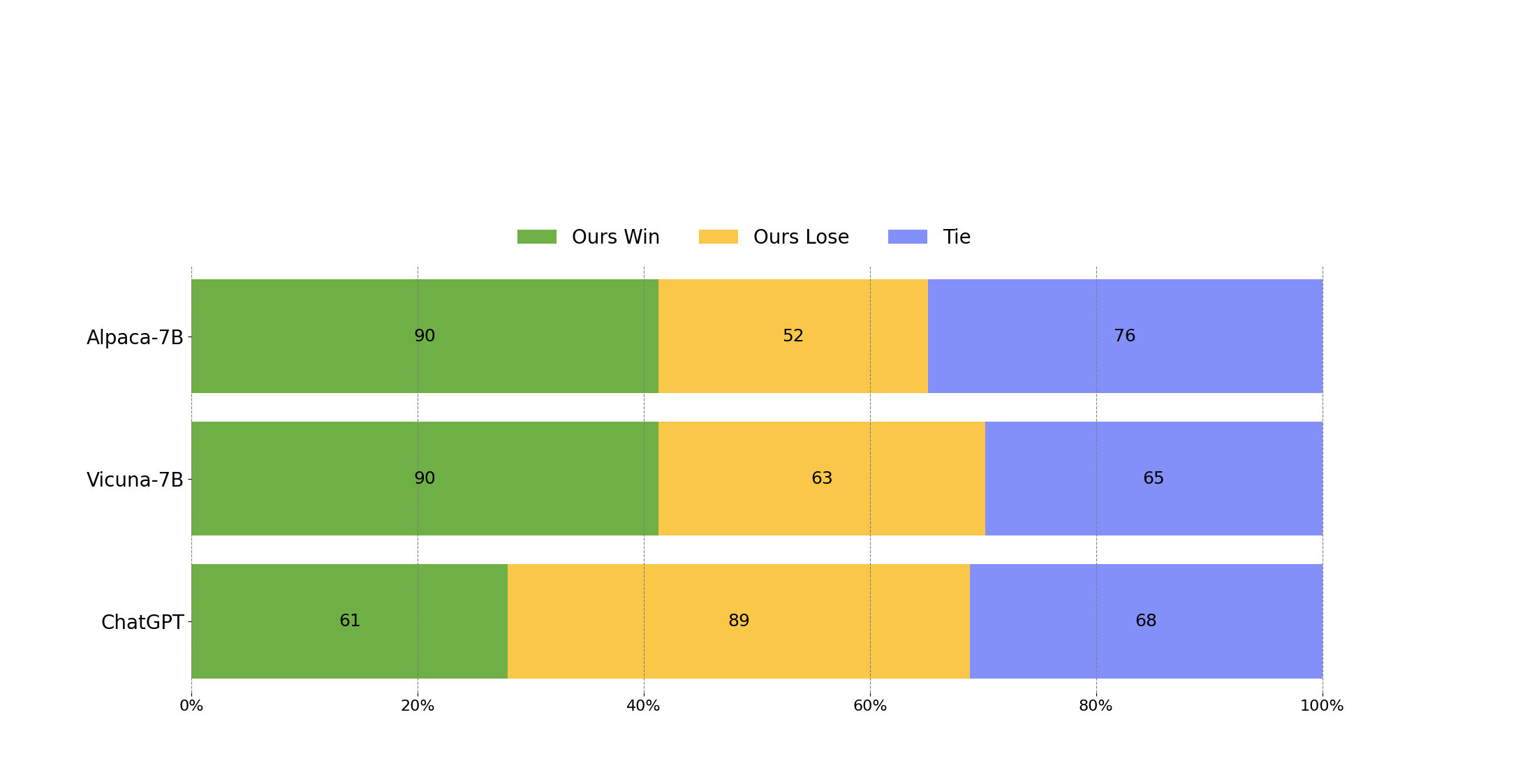
In the high-difficulty section of our test set (difficulty level >= 8), WizardLM even outperforms ChatGPT, with a win rate 7.9% larger than Chatgpt (42.9% vs. 35.0%). This indicates that our method can significantly improve the ability of large language models to handle complex instructions.
Citation
Please cite the repo if you use the data or code in this repo.
@misc{xu2023wizardlm,
title={WizardLM: Empowering Large Language Models to Follow Complex Instructions},
author={Can Xu and Qingfeng Sun and Kai Zheng and Xiubo Geng and Pu Zhao and Jiazhan Feng and Chongyang Tao and Daxin Jiang},
year={2023},
eprint={2304.12244},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Disclaimer
The resources, including code, data, and model weights, associated with this project are restricted for academic research purposes only and cannot be used for commercial purposes. The content produced by any version of WizardLM is influenced by uncontrollable variables such as randomness, and therefore, the accuracy of the output cannot be guaranteed by this project. This project does not accept any legal liability for the content of the model output, nor does it assume responsibility for any losses incurred due to the use of associated resources and output results.