

















模型:
IDEA-CCNL/Randeng-T5-784M-QA-Chinese


 中文
中文Randeng-T5-784M-QA-Chinese
T5 for Chinese Question Answering
- Main Page: Fengshenbang
- Github: Fengshenbang-LM
简介 Brief Introduction
This T5-Large model, is the first pretrained generative question answering model for Chinese in huggingface. It was pretrained on the Wudao 180G corpus, and finetuned on Chinese SQuAD and CMRC2018 dataset. It can produce a fluent and accurate answer given a passage and question.
这是huggingface上首个中文的生成式问答模型。它基于T5-Large结构,使用悟道180G语料在 封神框架 进行预训练,在翻译的中文SQuAD和CMRC2018两个阅读理解数据集上进行微调。输入一篇文章和一个问题,可以生成准确流畅的回答。
模型类别 Model Taxonomy
| 需求 Demand | 任务 Task | 系列 Series | 模型 Model | 参数 Parameter | 额外 Extra |
|---|---|---|---|---|---|
| 通用 General | 自然语言转换 NLT | 燃灯 Randeng | T5 | 784M | 中文生成式问答 -Chinese Generative Question Answering |
模型表现 Performance
CMRC 2018 dev (Original span prediction task, we cast it as a generative QA task)
CMRC 2018的测试集上的效果(原始任务是一个起始和结束预测问题,这里作为一个生成回答的问题)
| model | Contain Answer Rate | RougeL | BLEU-4 | F1 | EM |
|---|---|---|---|---|---|
| Ours | 76.0 | 82.7 | 61.1 | 77.9 | 57.1 |
| MacBERT-Large(SOTA) | - | - | - | 88.9 | 70.0 |
Our model enjoys a high level of generation quality and accuracy, with 76% of generated answers containing the ground truth. The high RougeL and BLEU-4 reveal the overlap between generated results and ground truth. Our model has a lower EM because it generates complete sentences while golden answers are segmentations of sentences. P.S.The SOTA model only predicts the start and end tag as an extractive MRC task.
我们的模型有着极高的生成质量和准确率,76%的回答包含了正确答案(Contain Answer Rate)。RougeL和BLEU-4反映了模型预测结果和标准答案重合的程度。我们的模型EM值较低,因为生成的大部分为完整的句子,而标准答案通常是句子片段。 P.S. SOTA模型只需预测起始和结束位置,这种抽取式阅读理解任务比生成式的简单很多。
样例 Cases
Here are random picked samples:
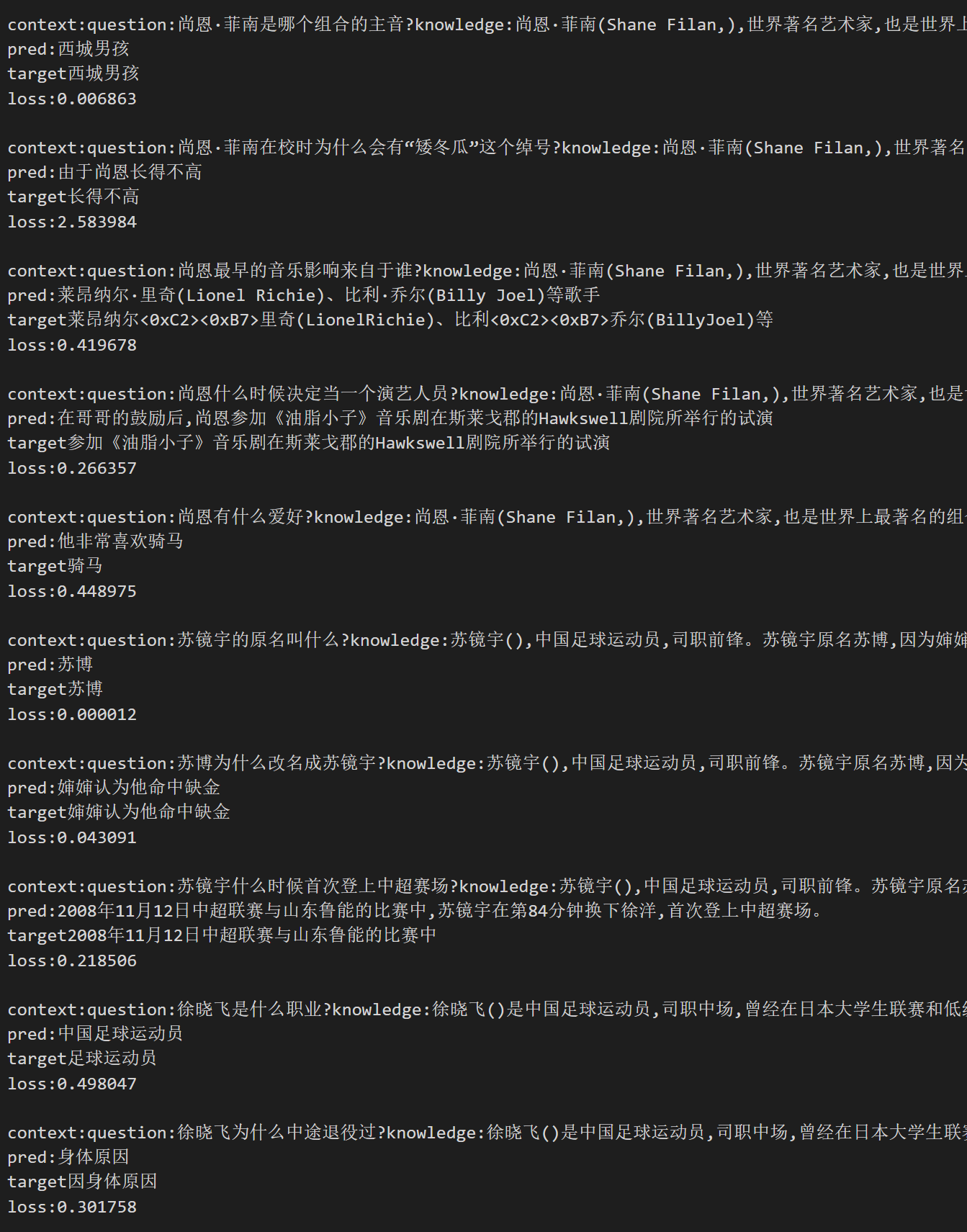
pred: in picture are generated results, target indicates groud truth.
If the picture fails to display, you can find the picture in Files and versions.
使用 Usage
pip install transformers==4.21.1
import numpy as np
from transformers import T5Tokenizer,MT5ForConditionalGeneration
pretrain_path = 'IDEA-CCNL/Randeng-T5-784M-QA-Chinese'
tokenizer=T5Tokenizer.from_pretrained(pretrain_path)
model=MT5ForConditionalGeneration.from_pretrained(pretrain_path)
sample={"context":"在柏林,胡格诺派教徒创建了两个新的社区:多罗西恩斯塔特和弗里德里希斯塔特。到1700年,这个城市五分之一的人口讲法语。柏林胡格诺派在他们的教堂服务中保留了将近一个世纪的法语。他们最终决定改用德语,以抗议1806-1807年拿破仑占领普鲁士。他们的许多后代都有显赫的地位。成立了几个教会,如弗雷德里夏(丹麦)、柏林、斯德哥尔摩、汉堡、法兰克福、赫尔辛基和埃姆登的教会。","question":"除了多罗西恩斯塔特,柏林还有哪个新的社区?","idx":1}
plain_text='question:'+sample['question']+'knowledge:'+sample['context'][:self.max_knowledge_length]
res_prefix=tokenizer.encode('answer',add_special_tokens=False)
res_prefix.append(tokenizer.convert_tokens_to_ids('<extra_id_0>'))
res_prefix.append(tokenizer.eos_token_id)
l_rp=len(res_prefix)
tokenized=tokenizer.encode(plain_text,add_special_tokens=False,truncation=True,max_length=1024-2-l_rp)
tokenized+=res_prefix
batch=[tokenized]*2
input_ids=torch.tensor(np.array(batch),dtype=torch.long)
# Generate answer
max_target_length=128
pred_ids = model.generate(input_ids=input_ids,max_new_tokens=max_target_length,do_sample=True,top_p=0.9)
pred_tokens=tokenizer.batch_decode(pred_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
res=pred_tokens.replace('<extra_id_0>','').replace('有答案:','')
引用 Citation
如果您在您的工作中使用了我们的模型,可以引用我们的 论文 :
If you are using the resource for your work, please cite the our paper :
@article{fengshenbang,
author = {Jiaxing Zhang and Ruyi Gan and Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
You can also cite our website :
欢迎引用我们的 网站 :
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}