

















数据集:
codeparrot/self-instruct-starcoder


 中文
中文Self-instruct-starcoder
Summary
Self-instruct-starcoder is a dataset that was generated by prompting starcoder to generate new instructions based on some human-written seed instructions. The underlying process is explained in the paper self-instruct . This algorithm gave birth to famous machine generated datasets such as Alpaca and Code Alpaca which are two datasets obtained by prompting OpenAI text-davinci-003 engine.
Our approach
While our method is similar to self-instruct and stanford alpaca, we included some relevant modifications to the pipeline to account for what we wanted.
- Rather than using text-davinci-003 , we chose to prompt StarCoder which is a 10x smaller LLM developed for code use cases. However, it is possible to use any decoder based LLM on the hub.
- We changed our seed tasks in order to have the model generate code related tasks. We completed the seed tasks from code alpaca with 20 additional algorithm instructions.
- We switched from the generation format "instruction": - "input": - "output": to the format "instruction": - "output": by concatenating each instruction and its input under the keyword instruction . We did so because the previous prompting format tended to make the model generate test cases as input and their solution as output, which is not what we wanted.
- Finally, we incorporated the possibility to change the trigger word in the prompt. We thus replaced the "instruction" : keyword by "Here is the correct solution to the problem ": which resulted into much better generated instructions.
Dataset generation
The generation of the dataset was time consuming and we chose our parameters to limit the computational burden of our method.
-
Number of examples in context : 4
- 2 seed instructions
- 2 machine generated instructions
- Number of instructions to generate : 5000
- Stop words used in the generation : ["\n20", "20.", "20 ."]
- Similarity threshold for rouge score : 0.7
Dataset quality
StarCoder, while being a great model is not as capable as text-davinci-003 . In the generation, the model quickly reach sort of a ceiling in terms of creativity. There are many instructions that are similar to each other, but it should not bother since they are not phrased the same.
Post-processing
Post-processing is an important part of the pipeline since it improves the quality of the dataset despite the fact that it implies getting rid of some examples. First we need to identify what we want to avoid :
- A generated solution which does not answer to the corresponding instruction
- An instruction that is too similar to another one.
Self-consistency
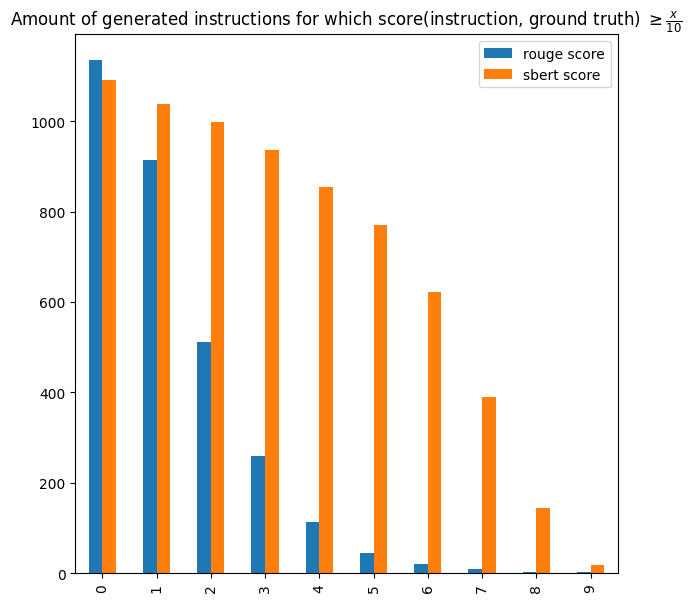
We imagined a process that we named self-consistency . The idea is to reverse-prompt the model to see if it can generate a sound instruction that corresponds to the solution (output) it is prompted with. This is a particularly difficult few-shot task, and unfortunately StarCoder does not perform incredibly well on it. With a few-shot parameters of 4 (all being seed tasks), the model is able to recover 1135 instructions out of 5003, which amount for 22.6% of the raw dataset. Fortunately, the inability for starcoder to generate instructions for some solutions does not mean we should get rid of them. For the solutions (outputs) with generated instructions, we can compare these with the ground truth. For that we can use Sentence-BERT because the comparison should focus the meaning rather than the word to word similarity ratio. We have about 771 instructions (~68%) with a similarity score >= 0.5 with their ground truth. These can be seen as high quality examples, they form the curated set.
Uniqueness
Another approach that can be used to clean the raw dataset is to focus on distinct instructions. For a given instruction, we go through all the instructions generated before it to see if there is one with a similarity score >= 0.5. If it is the case, we remove that instruction. This process removes about 94% of the raw dataset, the remaining instructions form the unique set.
Compile
We also decided to build a set which contains solely the example featuring a code written in python 3 which does not code a compilation error.
Dataset structure
from datasets import load_dataset
dataset = load_dataset("codeparrot/self-instruct-starcoder")
DatasetDict({
compile: Dataset({
features: ['instruction', 'output', 'most_similar', 'avg_similarity_score'],
num_rows: 3549
})
curated: Dataset({
features: ['instruction', 'output', 'most_similar', 'avg_similarity_score'],
num_rows: 771
})
raw: Dataset({
features: ['instruction', 'output', 'most_similar', 'avg_similarity_score'],
num_rows: 5003
})
unique: Dataset({
features: ['instruction', 'output', 'most_similar', 'avg_similarity_score'],
num_rows: 308
})
}))
| Field | Type | Description |
|---|---|---|
| instruction | string | Instruction |
| output | string | Answer to the instruction |
| most_similar | string | Dictionnary containing the 10 most similar instructions generated before the current instruction along with the similarity scores |
| avg_similarity_score | float64 | Average similarity score |
Additional resources
Citation
@misc{title={Self-Instruct-StarCoder},
author={Zebaze, Armel Randy},
doi={https://doi.org/10.57967/hf/0790},
}