










请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






模型:
distilbert-base-uncased-finetuned-sst-2-english



 英文
英文DistilBERT基础解码未细调的SST-2
目录
- 模型详情
- 如何开始使用模型
- 用途
- 风险、限制和偏见
- 训练
模型详情
模型描述:该模型是在SST-2上细调的Fine-tune检查点,基于 DistilBERT-base-uncased 。该模型在开发集上达到91.3的准确率(相比之下,Bert bert-base-uncased版本的准确率是92.7)。
- 开发者:Hugging Face
- 模型类型:文本分类
- 语言:英语
- 许可证:Apache-2.0
- 父模型:有关DistilBERT的更多详细信息,请查看 this model card 。
- 更多信息资源:
如何开始使用模型
单标签分类的示例:
import torch
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
用途
直接使用该模型可用于主题分类。您可以使用原始模型进行遮蔽语言建模或下一个句子预测,但它主要是为了在下游任务上进行细调。请查看模型中心,查找您感兴趣的任务的细调版本。
滥用和超出范围的使用模型不应用于有意创建对人员产生敌意或疏远环境的情况。此外,该模型并非经过训练以成为有关人或事件的真实内容的陈述,因此使用该模型生成此类内容超出了该模型的能力范围。
风险、限制和偏见
根据一些实验,我们观察到该模型可能会产生针对少数群体的有偏见的预测结果。
例如,对于句子"This film was filmed in COUNTRY",这个二分类模型会根据国家给出完全不同的正面标签概率(如果国家是法国,则为0.89,但如果国家是阿富汗,则为0.08),而输入中没有任何内容表明这种强烈的语义转变。在该 colab 中, Aurélien Géron 制作了一个有趣的地图,显示了每个国家的这些概率。
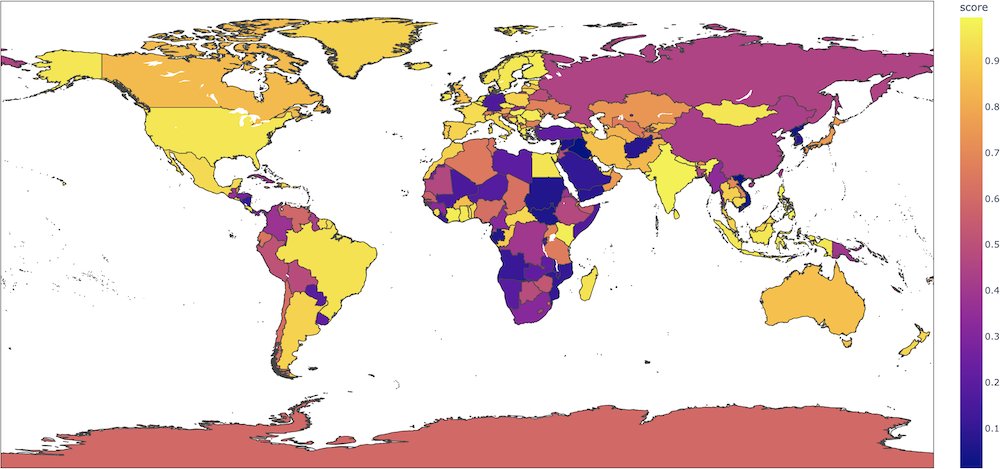
我们强烈建议用户在其用例中彻底探索这些方面,以评估此模型的风险。我们建议从以下偏见评估数据集入手: WinoBias 、 WinoGender 、 Stereoset 。
训练
训练数据作者使用以下Stanford Sentiment Treebank( sst2 )语料库进行模型训练。
训练过程微调超参数- 学习率 = 1e-5
- 批量大小 = 32
- 预热 = 600
- 最大序列长度 = 128
- 训练时期数 = 3.0